Web scraping quickly runs into limits, such as blocked requests, inconsistent access, and unreliable data. The right proxy setup helps solve that by distributing requests and making them harder to detect.
Here are the proxy providers that handle these challenges well, whether you’re dealing with large datasets, restricted sites, or more targeted data collection tasks.
Best Proxy Providers for Web Scraping: Key Findings
- Bright Data and Oxylabs sit at the enterprise end, combining large proxy networks with scraping APIs and automation tools for high-volume, restricted targets.
- Decodo, Webshare, NetNut, and IPRoyal cover a wide middle ground, with different trade-offs between pricing, session stability, ease of setup, and level of control.
- SOAX, MarsProxies, Rayobyte, and Nimble lean into specific strengths, whether that’s precise geo-targeting, simpler proxy setups, transparent infrastructure, or more automated data collection.
Why Proxies Are Non-Negotiable for Web Scraping at Scale
If you scrape the web without proxies, you’ll hit limits fast.
Most websites actively monitor traffic patterns and will trigger rate limits, CAPTCHAs, or outright IP bans when they detect hundreds or thousands of requests from a single IP address.
In fact, 39.1% of developers building scraping tools report using proxy providers specifically to avoid blocks and stay operational.
This is because proxies route requests through pools of different IPs, making traffic appear distributed and human-like.
Beyond simple access, proxies are critical for scale, accuracy, and reliability: they scrape larger datasets without interruptions, maintain consistent uptime for automated scripts, and help avoid data gaps caused by blocked requests.
Proxy Infrastructure vs. Managed Scraping APIs: Know What You’re Buying
When choosing a web scraping solution, first confirm what you’re actually paying for: proxy infrastructure, a managed scraping API, or both.
- Proxy infrastructure gives you raw IP addresses. You control routing, sessions, retries, and anti-bot handling, making it a better fit for teams with scraping code already in place and the technical capacity to manage it.
- A managed scraping API handles more of the workflow for you, including IP rotation, CAPTCHA solving, JavaScript rendering, block management, and structured data delivery. It’s better suited for teams that want to reduce maintenance or scale faster without adding engineering overhead.
Many leading providers, including Bright Data, Oxylabs, Decodo, NetNut, SOAX, Rayobyte, and Nimble, offer both infrastructure and managed APIs.
This gives you more flexibility to start with raw proxies, move to an API, or use both depending on the project.
Best Proxy Providers for Web Scraping Overview
Not all proxy providers are built for web scraping at scale.
The best options combine large, reliable IP pools, fast rotation, high success rates, and scraping-friendly policies that minimize blocks and downtime.
Below, I break down the proxy providers that consistently perform well for data extraction, automation, and geo-targeted scraping use cases in 2026.
| Proxy Provider | IPs Available | Proxy Types | Proxy Cost |
| 400M+ combined | Residential, Datacenter, ISP, Mobile | $4/GB | |
| 177M+ | Residential, Datacenter, ISP, Mobile | $4/GB | |
| 115M+ | Residential, Datacenter, ISP, Mobile | $6/mo for 2 GB | |
| 80M+ | Residential, Datacenter, ISP | $2.99/mo for 100 proxies | |
| 90M+ | Residential, Datacenter, ISP, Mobile | $3.53/GB | |
| Not publicly listed | Datacenter and residential proxies through Zyte API | $0.13 per 1,000 requests | |
| 191M+ | Residential, Datacenter, ISP, Mobile | $3.60/GB | |
| 32M+ | Residential, Datacenter, ISP, Mobile | $1.75/GB | |
| 40M+ | Residential, Datacenter, ISP, Mobile | $3.50/GB | |
| Undisclosed | Residential, Datacenter, ISP, Mobile | $8/GB |
1. Bright Data: Best for Enterprise-Grade Web Scraping
Bright Data is a widely used platform for large-scale web data extraction, combining proxy infrastructure with fully managed scraping tools.
Its Web Scraper API handles the full scraping process, including IP rotation, CAPTCHA solving, and data parsing, so teams don’t need to manage proxies or infrastructure manually.
Pricing:
- Free tier for 5K records
- Pay-as-you-go: $1.5 per 1K records
- Monthly plans: from $499/month with volume-based discounts
Get the most out of your data collection with 25% off using code APIS25.
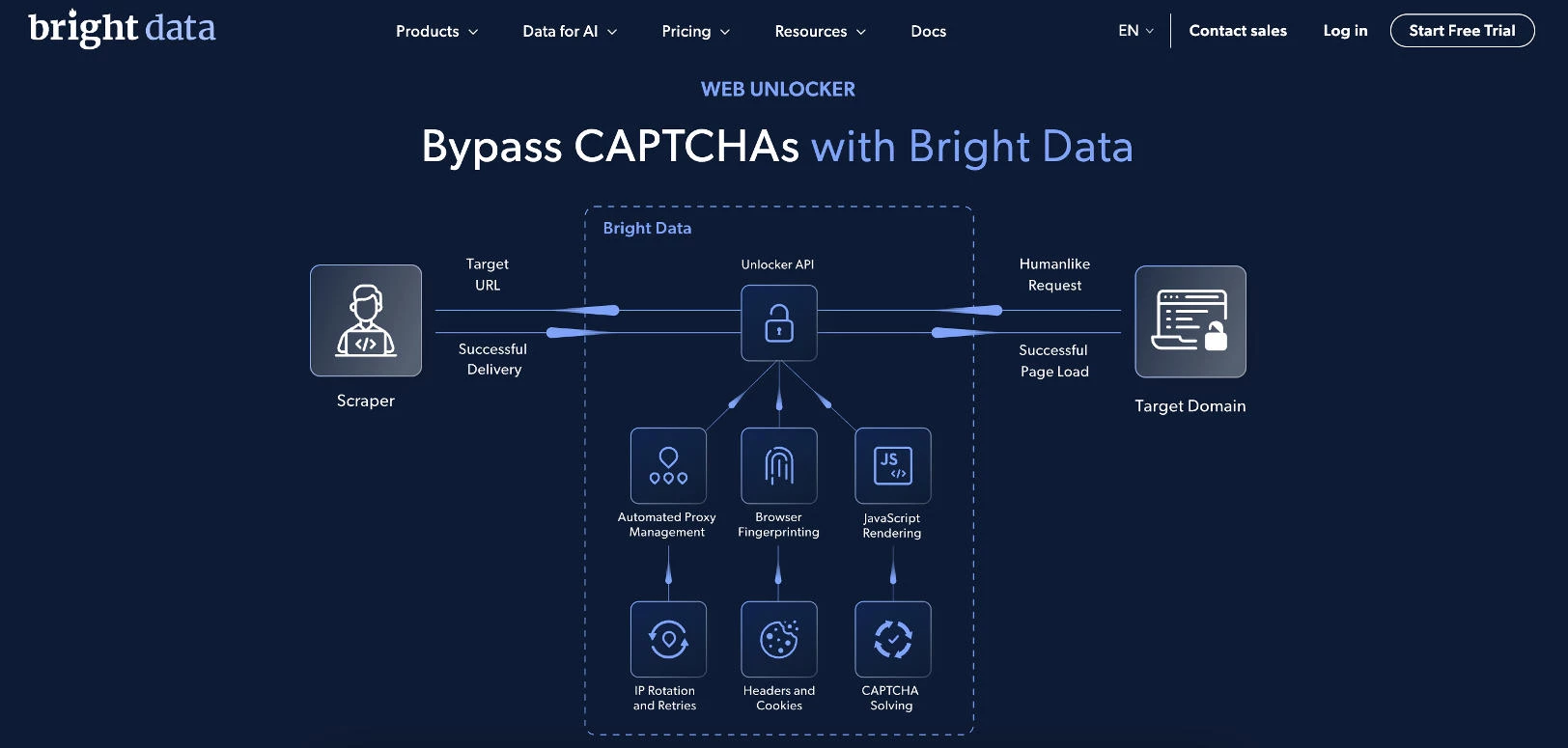
Notable Features
- Web Scraper API with automated data extraction and parsing
- Built-in IP rotation and CAPTCHA handling
- No-code and API-based scraping workflows
- Bulk request handling for large-scale jobs
- Data delivery in structured formats (CSV, NDJSON)
- 24/7 support and enterprise-grade infrastructure
Who’s It For?
Bright Data is best suited for enterprises, data teams, and agencies that need consistent large-scale data extraction without managing their own scraping infrastructure.
It works well for teams running high-volume scraping projects, feeding data into analytics pipelines, or collecting structured datasets from complex or protected websites.
2. Oxylabs: Best for Compliance-Conscious Data Collection
Oxylabs offers a Web Scraper API built for teams that need structured data from public websites without managing scraping infrastructure.
The product handles the full extraction flow, including access, parsing, and delivery of ready-to-use results.
Pricing:
- Free trial: up to 2,000 results
- Micro plan: from $0.50 per 1K results ($49/month)
- Starter plan: from $0.45 per 1K results ($99/month)
- Advanced plan: from $0.40 per 1K results ($249/month)
- Venture plan: from $0.37 per 1K results ($499/month)
- Business plan: from $0.30 per 1K results ($999/month)
- Corporate plan: from $0.25 per 1K results ($2,000/month)
- Custom plan: tailored pricing for high-volume needs
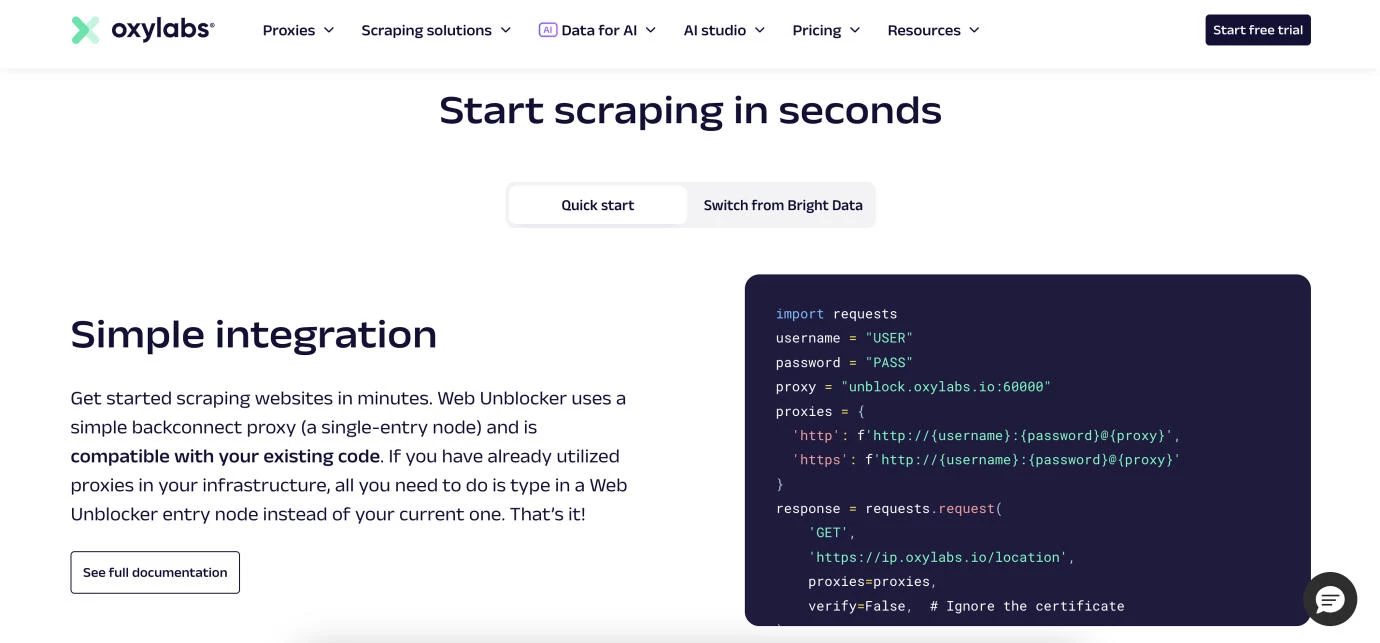
Its infrastructure is built for large-scale workloads, with an emphasis on reliability, security, and enterprise-grade controls.
The platform is supported by a global proxy network covering residential, ISP, mobile, and datacenter IPs, helping maintain access to geo-targeted and more restrictive websites.
Notable Features
- Web Scraper API for end-to-end data extraction
- Pay only for successful results
- Preconfigured target library with adjustable parameters
- Parsing support via Oxy Parser
- 99.9% API uptime
- 24/7 support
- SOC 2 Type 2 and GDPR-aligned infrastructure
Who’s It For?
Oxylabs is for enterprise teams, research groups, and organizations that need reliable data extraction with clear compliance and security standards in place.
3. Decodo: Best for Cost-Effective Scraping
Decodo is a great option if you want fast, reliable web scraping with pricing that stays accessible at lower volumes and scales as needs grow.
Known for its developer-friendly platform and competitively priced infrastructure, Decodo combines proxy access with a fully managed Web Scraping API that handles the entire data extraction process, including IP rotation, CAPTCHA bypassing, retries, and parsing.
Pricing:
- Free plan available
- Paid plans start from $19/month
- Usage-based pricing from $0.50 per 1K requests, decreasing with volume
- Custom plans available for high-volume needs
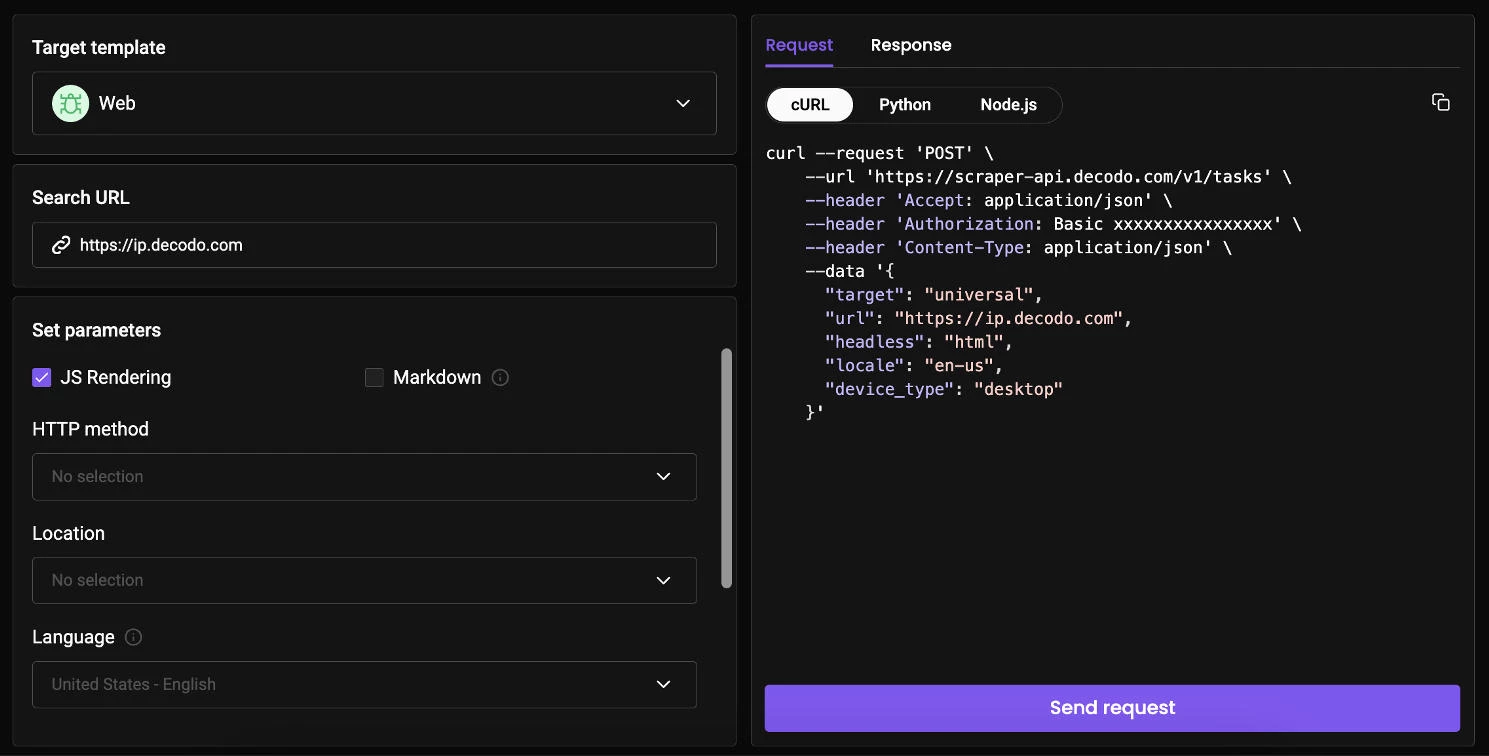
It supports high-volume scraping across complex targets, with infrastructure capable of managing up to 200 requests per second and a proxy pool of 125M+ IPs worldwide.
It delivers a reported 99.99% success rate and automatically manages anti-bot systems using browser fingerprinting, IP rotation, and retry logic, reducing manual intervention during data collection.
Decodo also focuses on usability, with ready-made templates and flexible API parameters that enable launching scraping tasks quickly without extensive setup.
Notable Features
- Web Scraping API with automatic proxy management and anti-bot handling
- 99.99% success rate
- Only pay for successful requests
- 125M+ IPs with global coverage
- Up to 200 requests per second
- 100+ pre-built scraping templates
- Output formats: HTML, JSON, CSV, PNG, XHR, Markdown
- JavaScript rendering and advanced browser fingerprinting
- AI integrations and LLM-ready markdown output
- 24/7 tech support and 14-day money-back guarantee
Who’s It For?
Decodo is for startups, agencies, and data teams that need high-speed scraping at scale while staying budget-conscious.
4. Webshare: Best for Developer-Friendly Scraping
Webshare is for teams that value affordability, control, and ease of use when building a scraping setup.
You can choose proxy types, adjust rotation, and scale usage directly from the dashboard.
Pricing:
- Free plan: 10 proxies + 1GB/month bandwidth (no credit card required)
- Datacenter: from $2.99/month (100 proxies at $0.0299/proxy)
- Static residential (ISP): from $0.30/IP/month
- Rotating residential: from $3.50/GB
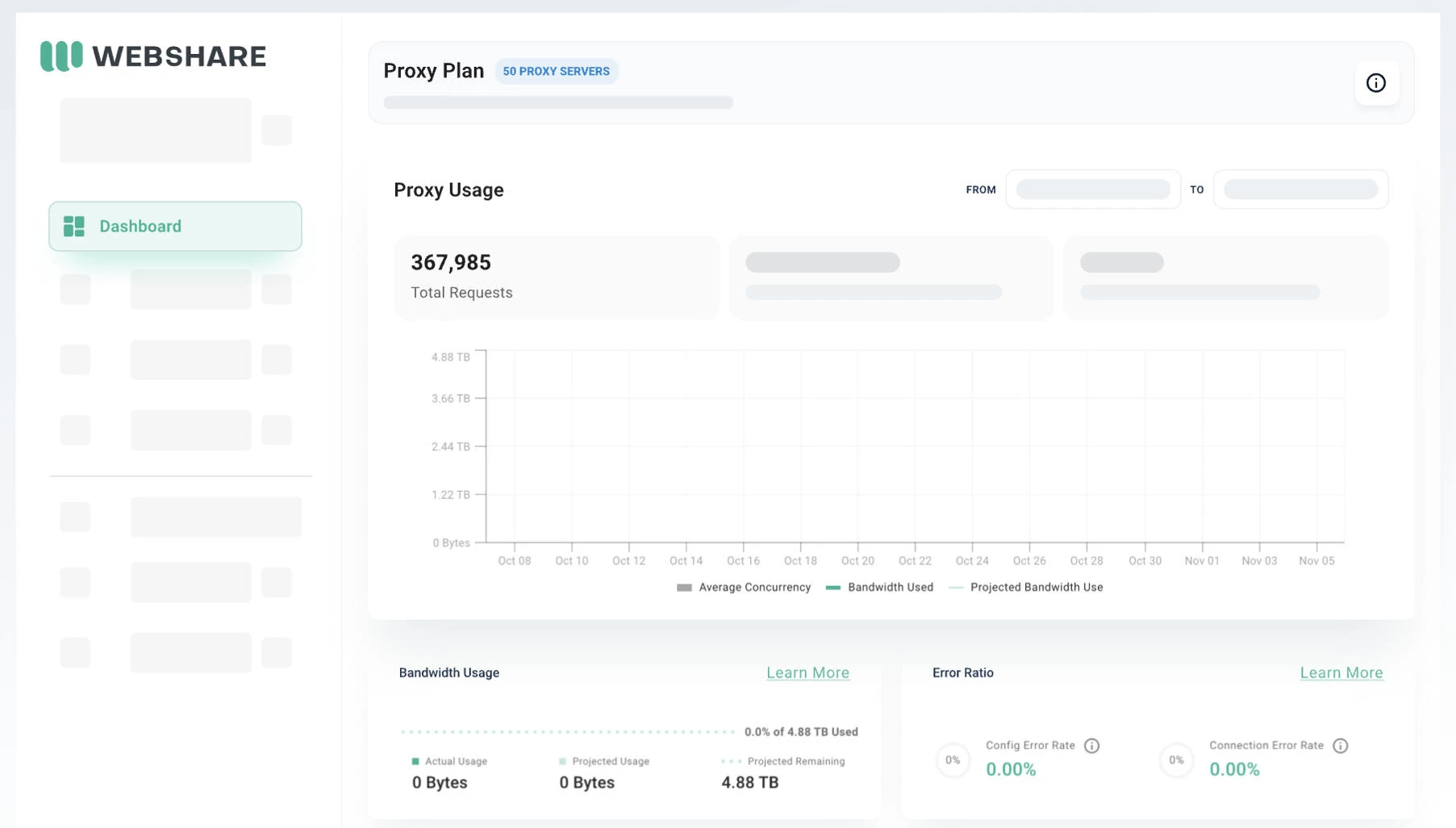
Webshare offers datacenter, ISP, and rotating residential proxies, letting you match proxy types to your scraping target.
Datacenter proxies cover 400K+ IPs across 50+ countries on a 100+ Gbps network, which is great for speed and volume. Rotating residential proxies extend that to 80M+ IPs across 195+ countries, better suited for geo-targeted or bot-protected targets.
The platform also supports standard protocols like HTTP and SOCKS5, API access, and a browser extension, making it easy to integrate into existing scraping workflows.
Notable Features
- Datacenter: 400K+ IPs, 50+ countries, 100+ Gbps network
- Residential: 80M+ IPs across 195+ countries
- 99.97% uptime guarantee across plans
- Permanent free plan with no credit card required
- Self-serve dashboard with custom plan configuration
- HTTP/SOCKS5 support and API integration
- Free Chrome extension for quick setup
- High concurrency up to 3,000 threads
- Usage tracking and proxy management tools
Who’s It For?
Webshare is for developers, startups, and smaller data teams that want predictable costs and direct control over how proxies are configured and used.
It works well for use cases like SEO monitoring, price tracking, data aggregation, and geo-restricted content access, especially when quick setup and simple proxy management are priorities.
5. NetNut: Best for High-Volume, Direct ISP Scraping
NetNut is for teams that need fast and stable web scraping across demanding or high-traffic targets.
Unlike traditional residential proxy networks, NetNut sources IPs directly from ISPs rather than peer-to-peer devices. This setup leads to lower latency, more stable sessions, and more predictable performance during long scraping runs.
Pricing:
- Website Unblocker: from $4.80
- SERP Scraper API: from $0.36
- B2B Data Scraper API: from $1.50
This architecture makes NetNut a great option for sustained data extraction workloads that rely on consistent connections rather than frequent IP rotation.
Its scraping stack includes a Website Unblocker for handling anti-bot systems, a SERP Scraper API for structured search data, and a B2B Data Scraper API for collecting company-level datasets.
These tools support geo-targeted data collection and help maintain access on sites that are sensitive to frequent IP changes or unstable sessions.
Notable Features
- Website Unblocker for bypassing anti-bot systems
- SERP Scraper API for real-time structured search data
- B2B Data Scraper API for company-level data collection
- High-speed & low-latency connections
- Stable sessions for long-running scraping tasks
- Global coverage across major regions
Who’s It For?
NetNut is best suited for enterprises, data providers, and analytics teams running large-scale scraping operations that depend on stable sessions and steady throughput.
It’s also for price intelligence, travel data, financial research, and similar use cases where maintaining consistent connections is critical.
6. Zyte: Best for Developer-Led Web Scraping Workflows
@andyhafell Transform your web stack with Al, start a trial with 10,000's of free requests! Use Zyte! #zyte#aiscraping#aitransformation♬ Epic Music(863502) - Draganov89
Zyte is a full-stack web scraping platform built for teams that want to collect web data without handling proxy rotation, browser rendering, or extraction logic manually.
Its Zyte API combines automatic unblocking, built-in headless browser support, AI-powered data extraction, and proxy management in one workflow, making it especially useful for developers already working with Scrapy or custom scraping pipelines.

Pricing:
- Pay-as-you-go: from $0.13 to $1.27 per 1,000 requests for HTTP response body
- Browser-rendered requests: from $1.01 to $16.08 per 1,000 requests
Notable Features
- Full-stack Zyte API for unblocking, rendering, and extraction
- Automatic proxy rotation and retry handling
- Built-in headless browser for JavaScript-heavy websites
- AI-powered data extraction
- Scrapy and Scrapy Cloud compatibility
- Ban detection, session support, and geolocation options
- Only charges for successful responses
Who’s It For?
Zyte is best suited for developers, data teams, and companies that need reliable web scraping infrastructure without building and maintaining every layer in-house.
It works well for teams using Scrapy, running custom crawlers, collecting structured web data at scale, or scraping websites that require JavaScript rendering, proxy management, and anti-ban handling in one setup.
7. SOAX: Best for Precise Geo-Targeted Scraping
SOAX is for teams that need fine-grained control over location, ISP, and session behavior when scraping the web.
Its network is designed around targeting flexibility, with options to specify countries, cities, regions, and even individual ISPs, which is useful for collecting highly localized or segmented datasets.
Pricing:
- Web Data API: from $0.90 per 1K requests
SOAX combines its proxy network with a Web Data API, enabling you to extract structured data while controlling how requests are routed and rotated.
The platform supports residential, mobile, and datacenter IPs, along with configurable rotation and session settings that help manage anonymity and session stability for each scraping task.
SOAX stands out for its targeting precision, clean proxy pools, and detailed configuration options, making it a reliable option when data accuracy depends on exact location or network conditions.
Notable Features
- City-, region-, and ISP-level geo-targeting
- Configurable IP rotation and session persistence
- Web Data API for structured data extraction
- Frequently refreshed proxy pools
- API access with detailed usage controls
Who’s It For?
SOAX fits teams working on ad verification, localized SERP tracking, market research, and eCommerce intelligence, in which location accuracy directly affects results.
8. IPRoyal: Best for Long-Session Residential Scraping
IPRoyal focuses on stable residential connections, making it a good option for scraping tasks that depend on longer session durations and consistent IPs.
It’s commonly used when maintaining a consistent identity over time is important, such as tracking changes, monitoring listings, or collecting data without frequent interruptions.
Pricing:
- ISP proxies: from $2.40 per proxy
- Rotating residential proxies: from $1.75/GB
- Datacenter proxies: from $1.39 per proxy
- Mobile proxies: from $10.11/day
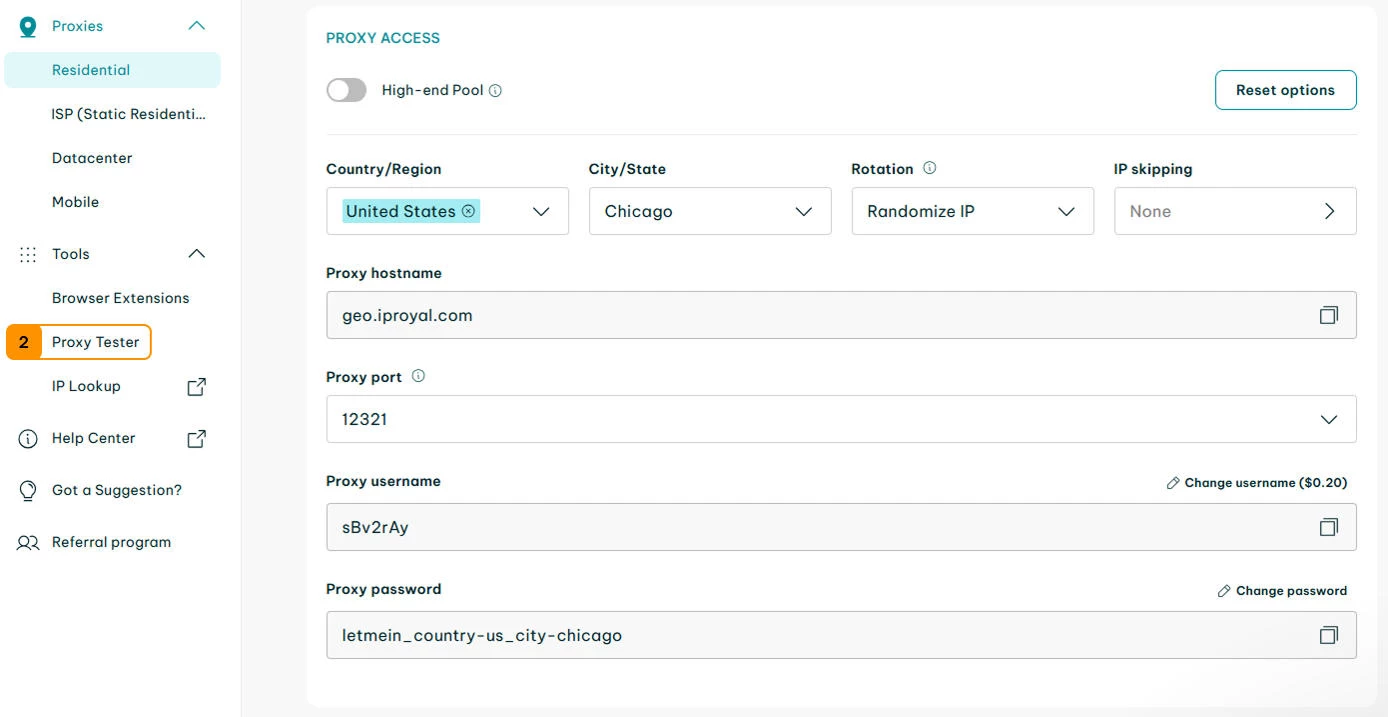
Its residential proxy network supports country-level geo-targeting and flexible session control, helping maintain access to sites that limit frequent IP switching.
IPRoyal also offers non-expiring residential traffic, allowing bandwidth to be used at any pace.
Notable Features
- Long session support for stable scraping
- Non-expiring residential bandwidth
- Country-level geo-targeting
- Simple dashboard with API access
- Ethically sourced residential IPs
Who’s It For?
IPRoyal is commonly used for SEO monitoring, price tracking, and market research tasks that depend on consistent sessions and predictable usage.
9. Rayobyte: Best for US-Focused Scraping
Rayobyte centers on transparent infrastructure and consistent performance, particularly for U.S.-centric scraping workloads.
Formerly known as Blazing SEO, the platform has shifted toward compliance-led practices with clearly documented proxy sourcing and infrastructure.
Pricing:
- Web Scraping API: usage-based (per request)
Rayobyte’s scraping offering combines its proxy network with a Web Scraping API that handles data extraction while maintaining control over request routing and execution.
Its network is especially recognized for datacenter proxy performance, offering high speeds and consistent uptime for targets that don’t require residential IPs. Residential proxies are also available for cases that need a higher level of anonymity.
The platform provides visibility into how its infrastructure operates, with clear documentation and ownership of IP resources.
Notable Features
- Web Scraping API for automated data extraction
- High-performance datacenter proxy infrastructure
- Strong U.S.-based IP coverage
- Transparent proxy sourcing and documentation
- API access with self-managed controls
Who’s It For?
Rayobyte works well for developers, agencies, and businesses running scraping projects that don’t rely on heavy anti-bot evasion.
It’s a good match for SEO data collection, market research, and monitoring tasks that depend on speed and predictable performance.
10. Nimble: Best for AI-Powered Data Collection
Nimbleway takes an automation-first approach to web scraping, combining proxy infrastructure with AI-driven data collection tools.
Instead of relying on manual setup, the platform adapts to blocking patterns, request failures, and site changes, helping keep data pipelines running with minimal intervention.
Pricing:
- Web Search Agents: from $3 per 1,000 pages
- Search API (Search): from $1.50 per 1,000 inputs
- Search API (Answer): from $4 per 1,000 queries
- Extract & Crawl APIs: from $0.90–$1.45 per 1,000 URLs (depending on complexity)
Nimble’s platform is built around automated request orchestration, handling retries, CAPTCHA, and rendering without requiring manual tuning.
It also focuses on structured output, delivering data in formats that can be fed directly into analytics workflows, pipelines, or AI systems.
Notable Features
- AI-driven request orchestration and blocking mitigation
- Automated handling of CAPTCHAs, retries, and failures
- Structured data delivery via APIs
- JS rendering and stealth drivers for complex sites
- Built-in support for scalable data pipelines
Who’s It For?
Nimbleway works well for organizations building data products, market intelligence platforms, or analytics pipelines that rely on continuous and automated data collection.
Best Proxy Providers for Web Scraping: Final Thoughts
To determine the top proxy providers of 2026, we conducted a thorough evaluation based on five key factors:
- Performance and speed: To assess speed, efficiency, and reliability, we tested response times and success rates across various websites, including highly restricted platforms.
- Reliability and security: Uptime, IP rotation, and ban resistance were measured to ensure uninterrupted access while maintaining strong anonymity and protection against detection.
- Geo-targeting capabilities: Providers were evaluated on their ability to offer country, city, and ISP-level targeting, ensuring precision for localized data collection.
- Ease of use and customer support: We reviewed dashboards, integration options, and API functionality while analyzing customer support responsiveness via live chat, email, and ticketing systems.
- Pricing and scalability: We compared pricing structures, traffic limits, and bulk discounts to determine affordability and scalability for businesses of all sizes.
By applying this framework, we identified the most efficient, reliable, and cost-effective proxy providers, ensuring businesses can make informed decisions based on their specific web scraping and data collection needs.
![]()
Our team ranks agencies worldwide to help you find a qualified partner. Visit our Agency Directory for the top IT services companies, as well as:
- Top IT Services for Startups
- Top Managed IT Service Providers
- Top Healthcare IT Services
- Top IT Services for Financial Industry
- Top IT Services Companies in Dallas
The Best Proxy Providers for Web Scraping FAQs
1. Why are proxies needed for web scraping?
Proxies are essential in web scraping to mask the scraper's IP address, preventing IP bans and enabling access to geo-restricted content. They distribute requests across multiple IPs, reducing the risk of detection and ensuring uninterrupted data collection.
2. What are the differences between proxy types?
- Datacenter Proxies: These originate from data centers and offer high speed and availability but are more easily detected and blocked by websites.
- Residential Proxies: Sourced from real residential devices, they provide higher anonymity and are less likely to be blocked, making them suitable for accessing restricted or sensitive data.
- Mobile Proxies: These come from mobile devices connected to cellular networks, offering the highest level of anonymity and are ideal for tasks requiring mobile IP addresses.
3. When should you choose between free vs. paid proxies?
Free proxies might suffice for small-scale or non-critical scraping tasks but often suffer from instability, slower speeds, and a higher risk of IP bans. While incurring costs, paid proxies provide reliability, speed, and enhanced security, making them preferable for large-scale or sensitive data extraction.
4. What is the number of proxies needed for large-scale scraping?
The required number of proxies depends on the scraping scale and target site restrictions. A general guideline is to use one proxy per 100 requests per day, but this may vary based on specific needs and goals.
5. What’s the difference between proxy-based scraping and scraping APIs?
Proxy-based scraping requires you to manage request logic, retries, and anti-bot handling yourself, using proxies to distribute traffic and avoid detection.
Scraping APIs, on the other hand, handle these layers for you by managing IP rotation, CAPTCHAs, and data extraction, often returning structured results.
The right choice depends on how much control you need versus how much setup and maintenance you want to avoid.