Web data is how businesses price smarter, track competitors, uncover leads, and spot trends before everyone else.
But here’s the problem: not all web scraping tools are built the same.
Best Web Scraping Tools: Key Findings
- Bright Data leads for serious, scalable data extraction, while Oxylabs and Zyte focus on stability and compliance for high-volume, recurring scraping projects.
- Apify and ScrapingBee offer flexible, developer-friendly workflows, balancing customization with ease of deployment.
- Octoparse, Browse AI, Firecrawl, HasData, and Import.io prioritize accessibility and structured outputs, ideal for users who need actionable data without maintaining complex infrastructure.
How Web Scraping Is Powering Smarter Decisions in 2026
In 2026, web scraping has moved from a niche technical tactic to a real competitive advantage.
Businesses use it to track pricing shifts, monitor competitors, analyze search visibility, and uncover new leads, often in near real time.
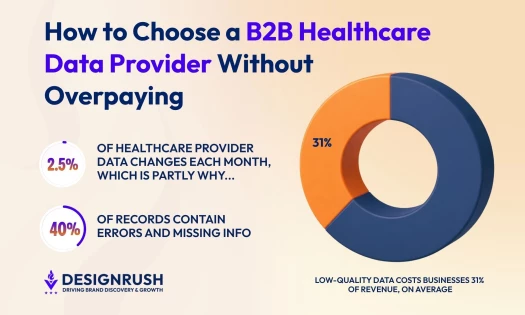
Its importance comes down to data quality. According to Gartner, poor data quality costs organizations an average of $12.9 million per year.
When your insights are flawed, your decisions are too. The right scraping tools help ensure the data feeding your marketing, operations, and strategy is accurate, timely, and reliable.
In this guide, we break down the 10 best web scraping tools in 2026 to help you choose the one that aligns with your goals, technical comfort level, and growth ambitions.
1. Bright Data: Best Overall
Bright Data is built for businesses that need reliable, compliant, and highly accurate web data extraction at scale. Its infrastructure is built to handle complex websites, dynamic content, and anti-bot protections without constant manual intervention.
They serve customers worldwide, including startups and Fortune 500 companies, and are widely used in production environments.
Unlike lightweight scraping tools, Bright Data combines scraping APIs, automation, and proxy infrastructure into a unified ecosystem.
This makes it especially powerful for price monitoring, competitive research, lead generation, and marketplace intelligence
Pricing:
- Free trial available (no credit card required)
- Pay-as-you-go from $1/1K records.
- Subscription plans from $499/month for teams scaling operations.
Special Offer: Ready to scale your data collection? Get 25% off when you use code APIS25 at checkout.
Notable Features
- Customizable scraping APIs for SERP, eCommerce, and social platforms
- MCP Server integration (free) for AI agents like Claude, LangGraph, and Google ADK
- LLM-ready datasets and 50PB+ Web Archive for AI training and fine-tuning
- Petabyte-scale infrastructure built for AI models, pipelines, and data workflows
- Industry-leading compliance stack, including GDPR, CCPA, ISO 27001, SOC 2, plus a public Trust Center
Who’s It For?
Bright Data is built for organizations that treat web data as critical infrastructure.
For regulated industries or enterprise buyers with strict governance requirements, its Trust Center, PwC-audited compliance practices, and rigorous KYC processes make it a strong fit for high-compliance environments.
Ariel Shulman, Chief Product Officer at Bright Data, emphasizes the importance of robust infrastructure for data collection:
“Teams are increasingly made aware of the complexities of extracting clean, structured data at scale from the public web.
Handling IP blocks and geo-targeting can be a constant effort without the right infrastructure in place, and teams are moving away from those to more advanced data solutions.”
Bright Data is ideal for:
- eCommerce brands monitoring prices across Amazon, Walmart, and eBay
- Fortune 500 companies and AI labs (including leading LLM teams)
- Financial services firms operating under GDPR and CCPA requirements
- Agencies running competitive intelligence
2. Apify: Best for Customizable Scraping Workflows
Apify strikes a strong balance between flexibility and usability, making it a favorite for users who want more control over how their web scraping runs. Instead of rigid templates, it allows customizable workflows that can adapt to different site structures and scraping goals.
Its marketplace of ready-made scraping “Actors” helps users launch common data extraction tasks quickly, from eCommerce listings to social media data. This reduces setup time while still allowing room for deeper customization when needed.
Pricing:
- Free
- Starter: $29/month
- Scale: $199/month
- Business: $999/month
Notable Features
- Extensive marketplace for common scraping tasks
- Built-in scheduling and automation for recurring jobs
- Cloud-based execution with no local setup required
- Flexible data export formats (JSON, CSV, Excel, integrations)
Who’s It For?
Apify is ideal for startups, researchers, marketers, and small-to-midsize businesses that need repeatable, customizable scraping workflows. It’s particularly useful for product monitoring, lead generation, marketplace tracking, and content aggregation.
3. Oxylabs: Best for Built-In Compliance
Oxylabs is a strong choice for businesses that need consistent, large-scale web scraping without sacrificing stability. It’s designed to handle complex websites and frequent data pulls while maintaining structured, reliable output for analytics and monitoring.
For growth-focused businesses, it delivers dependable performance and clear compliance practices, making it a practical option for sustained, high-volume data gathering.
Pricing:
- Free (up to 2,000 results)
- Paid plans start at $8/GB
Notable Features
- Pre-configured scraping solutions for eCommerce and SERPs
- Advanced anti-blocking and request retry systems
- Structured data parsing for cleaner outputs
- Extensive geo-targeting options for localized data collection
Who’s It For?
Oxylabs is ideal for data-driven businesses that rely on frequent, high-volume scraping. It’s great for users who need consistency, uptime, and clean datasets.
4. Octoparse: Best for No-Code Visual Web Scraping
Octoparse is designed for those who want powerful web scraping without writing code. Its visual, point-and-click interface allows users to select elements directly from a webpage and build automated extraction workflows in minutes.
For non-technical users, Octoparse removes the traditional barrier to entry while still supporting more advanced workflows when projects grow in complexity.
Pricing:
- Free
- Standard: $83/month
- Professional: $299/month
- Enterprise: Custom pricing
Notable Features
- Visual task builder with auto-detection of page elements
- Template library for popular websites and marketplaces
- IP rotation and CAPTCHA handling built in
- Export options to Excel, CSV, databases, and integrations
Who’s It For?
Octoparse doesn’t require technical setup or scripting knowledge. It’s ideal for marketers, ecommerce operators, sales teams, and researchers who need structured web data but don’t have development resources.
5. ScrapingBee: Best for Headless Browser Scraping
ScrapingBee is built for individuals and growing businesses that want clean, reliable web scraping without managing infrastructure. It handles headless browsers, proxy rotation, and JavaScript rendering behind a simple API, making it easy to extract data from modern, dynamic websites.
Instead of stitching together proxies and automation tools, users send a request and receive structured HTML or rendered content.
This reduces setup time and technical overhead, especially for developers building SaaS products, analytics tools, or internal dashboards.
Pricing:
- Freelance: $49/month
- Startup: $99/month
- Business: $249/month
- Business+: $599/month
Notable Features
- Automatic proxy rotation built into every request
- Premium and stealth proxy options for tougher sites
- Customizable request headers and geolocation targeting
Who’s It For?
ScrapingBee is best for developers, startups, and data-driven small businesses that need scalable web scraping without managing servers or proxy pools.
It’s particularly effective for scraping JavaScript-heavy sites, monitoring competitors, extracting product data, and powering internal tools or lightweight SaaS platforms.
6. Firecrawl: Best for Clean, Structured Data Extraction
Firecrawl is built for those who want clean, structured content from entire websites without complex setup. Instead of focusing on proxies or heavy infrastructure, it specializes in crawling pages and converting them into organized, readable formats like Markdown or structured JSON.
This makes it particularly useful for content aggregation, research, internal knowledge bases, and data preparation workflows. Users can quickly extract usable text from blogs, documentation sites, or resource libraries.
Pricing:
- Free
- Hobby: $19/month
- Standard: $99/month
- Growth: $399/month
@nathanhodgson_ Firecrawl cleans up messy scraped data automatically and plugs right into your n8n workflows. It handles JavaScript-rendered sites and outputs clean JSON or Markdown ready for LLMs—plus it’s open-source. #ai#artificialintelligence#n8n#aiautomation#aitools♬ dereal (Super Slowed) - FutureVille & .diedlonely
Notable Features
- Automatic full-site crawling with link discovery
- Clean Markdown conversion for easy reuse
- Structured output optimized for databases or content systems
- Lightweight setup with minimal configuration required
- Scalable crawling without manual workflow building
Who’s It For?
Firecrawl shines when your goal isn’t just scraping pages, but actually using the content afterward.
Content marketers can turn entire blogs into structured research assets, SaaS teams can transform documentation into searchable knowledge hubs, and researchers can quickly compile competitor content into clean, analysis-ready datasets.
7. HasData: Best for SERP and eCommerce Data
HasData focuses on delivering structured search engine and eCommerce data without complex configuration. It simplifies the process of collecting rankings, product listings, and marketplace information in a clean, usable format.
Instead of building scrapers from scratch, users can quickly pull organized datasets tailored to common business use cases like SEO tracking and price monitoring. This significantly reduces setup time and ongoing maintenance.
Pricing:
- Free
- Startup: $49/month
- Business: $99/month
- Enterprise: $249/month
Notable Features
- Pre-structured SERP datasets across major search engines
- Localized search tracking with country and device targeting
- Dedicated eCommerce data endpoints for product monitoring
- Scalable request handling with consistent response formatting
Who’s It For?
HasData makes sense when rankings, product listings, and marketplace visibility directly impact revenue.
SEO specialists can monitor keyword performance at scale, eCommerce operators can track competitors’ pricing in near real time, and agencies can feed structured search data straight into client reports
8. Zyte: Best for Low-Maintenance Web Scraping
Zyte focuses on automation and resilience, helping users collect structured web data even as websites update layouts or introduce anti-bot protections. For users who value consistency over manual tweaking, it delivers dependable scraping with minimal operational overhead.
Zyte emphasizes stability and long-term performance. This makes it especially appealing for recurring data projects like product tracking, marketplace monitoring, and content aggregation.
Pricing:
- Zyte API: Starts at $0.13/1K responses
- Scrapy Cloud Starter: Free
- Scrapy Cloud Professional: $9/unit/month
- Zyte Data Standard: $500/month
- Zyte Data Professional: $1,000/month
Notable Features
- Automatic handling of bans and anti-scraping defenses
- Smart request management to reduce failed extractions
- Structured data parsing for cleaner datasets
- Built-in compliance and responsible crawling practices
Who’s It For?
Zyte works well for users that rely on recurring, long-term data collection. eCommerce brands tracking competitors, analysts monitoring marketplaces, and startups building data-driven products can focus on insights instead of scraper maintenance.
9. Browse AI: Best for Website Monitoring
Browse AI makes web scraping feel less like coding and more like training a virtual assistant. Users simply record their actions on a webpage, and the platform turns those steps into an automated data extraction workflow.
This approach lowers the technical barrier significantly, making it accessible to business owners, marketers, and operations teams who want data without writing scripts. It’s particularly effective for recurring data pulls from structured websites.
For small businesses that want fast setup and minimal maintenance, Browse AI delivers practical automation without the complexity of traditional scraping tools.
Pricing:
- Free
- Personal: $48/month
- Professional: $87/month
- Premium: Starts at $500
View this post on Instagram
Notable Features
- Robot training system that learns from recorded actions
- Automatic monitoring with change detection alerts
- Prebuilt robots for common sites and use cases
- Scheduled runs with data syncing to spreadsheets and apps
Who’s It For?
Browse AI is a strong fit for founders, marketers, eCommerce operators, and ops teams who want to monitor competitor prices, track listings, or extract directory data without relying on developers.
It’s especially compelling when speed matters, and the goal is ongoing website monitoring rather than one-time bulk scraping.
10. Import.io: Best for Data Extraction Without Coding
Import.io focuses on simplifying extraction through a guided interface, so users can turn websites into clean datasets quickly and consistently.
Rather than emphasizing infrastructure management, Import.io centers on usability and reliability. Users can define what data they need, and the platform handles the extraction process, reducing technical friction and ongoing maintenance.
Pricing is available by request.
Notable Features
- Point-and-click data field selection for quick setup
- Automated extraction workflows with minimal configuration
- Built-in data transformation and cleaning tools
- Structured output designed for immediate analysis
- Cloud-based management with centralized project control
Who’s It For?
Import.io works well for business users, analysts, and small teams that need consistent web data without writing code.
It’s especially effective for market research, competitor tracking, pricing analysis, and reporting workflows where structured datasets are more important than the scraping process itself.
Best Web Scraping Tools Overview
| Tool | Best For | Prebuilt Templates | Scheduling/ Automation | Anti-bot Handling | Pricing Starts At |
| Bright Data | Overall scalability & accuracy | ✅ | ✅ | ✅ | $1/1K records |
| Apify | Customizable workflows | ✅ | ✅ | ❌ | $29/month (free plan available) |
| Oxylabs | Compliance & stability | ✅ | ❌ | ✅ | $8/GB (free plan available) |
| Octoparse | No-code scraping | ✅ | ✅ | ✅ | $83/month (free plan available) |
| ScrapingBee | Headless browser scraping | ❌ | ❌ | ❌ | $49/month |
| Firecrawl | Clean content extraction | ❌ | ✅ | ❌ | $19/month (free plan available) |
| HasData | SERP & eCommerce data | ✅ | ❌ | ✅ | $49/month (free plan available) |
| Zyte | Low-maintenance scraping | ❌ | ✅ | ✅ | $0.13/1K responses |
| Browse AI | Website monitoring | ✅ | ✅ | ❌ | $48/month (free plan available) |
| Import.io | Guided no-code extraction | ❌ | ✅ | ❌ | Available by request |
Web Scraping Tips and Best Practices
Web scraping can be incredibly powerful for individuals and businesses, but only when it’s done strategically.
The right approach helps you collect accurate data, avoid disruptions, and stay compliant while minimizing wasted time and effort.
These best practices will help you build reliable workflows without unnecessary complexity:
- Start with clear goals: Identify the exact fields you need (price, SKU, ranking, email, etc.), how often you need them, and how the data will be used before selecting a scraping tool.
- Respect website terms and robots.txt: Review the site’s terms of service and robots.txt file to understand access guidelines, rate limits, and restrictions to reduce legal and operational risks.
- Use built-in scheduling features: Automate recurring scraping jobs on a daily, weekly, or hourly basis so your datasets stay current without manual exports or constant monitoring.
- Limit request frequency: Space out requests and use reasonable crawl delays to reduce the risk of IP blocks, incomplete data pulls, or triggering anti-bot protections.
- Choose structured outputs: Export data in clean formats like CSV or JSON so it integrates smoothly with spreadsheets, BI tools, dashboards, or internal reporting systems.
- Test on small samples first: Run limited test jobs to verify data accuracy, formatting, and completeness before committing credits or scaling to thousands of pages.
- Monitor for site changes: Regularly check your scraping workflows for broken selectors, missing fields, or layout updates, so data remains accurate and consistent over time.
Web Scraping Tools: Final Thoughts
The best web scraping tool in 2026 is the one that actually fits how you work.
Some teams need serious scale and resilience. Others just want a clean, no-code way to pull competitor prices or SEO data.
The real win is choosing a platform that integrates smoothly into your workflow and delivers usable data, not just impressive features on paper.
![]()
Our team ranks agencies worldwide to help you find a qualified partner to implement the latest AI solutions. Visit our Agency Directory for the Top IT Services Companies, as well as:
- Top IT Consulting Companies
- Top IT Outsourcing Companies
- Top IT Services for Startups
- Top IT Services for Financial Industry
- Top IT Services Companies in Florida
Web Scraping Tools FAQs
1. Is web scraping legal?
Web scraping is generally legal when collecting publicly available data, but usage must comply with website terms, copyright laws, and data privacy regulations. Always review robots.txt policies and avoid scraping personal or protected information.
2. What’s the difference between no-code and developer-focused scraping tools?
No-code tools like Octoparse and Browse AI use visual builders and automation workflows. Developer-focused tools like Apify and ScrapingBee allow deeper customization but require technical implementation.
3. Can web scraping tools handle JavaScript-heavy websites?
Yes. Tools like Bright Data, ScrapingBee, and Zyte are designed to render JavaScript-heavy sites, making them effective for modern ecommerce platforms and dynamic web applications.
4. What’s the biggest risk in web scraping?
The most common issues are IP blocking, site structure changes, and inconsistent data formatting. Choosing tools with built-in resilience and monitoring reduces these risks significantly.